I’m going to talk about reflection-heavy libraries; I will describe the scenario I’m talking about - as it is commonly used today, the status quo, giving a brief overview of the pros and cons of this, and then present the case that times have changed, and with new language and runtime features: it may be time to challenge our way of thinking about this kind of library.
I’m a code-first kind of developer; I love the inner-loop experience of being able to tweak some C# types and immediately have everything work, and I hate having to mess in external DSLs or configuration files (protobuf/xml/json/yaml/etc). Over the last almost-two-decades, I’ve selected or written libraries that allow me to work that way. And, to be fair, this seems to be a pretty common way of working in .NET.
What this means in reality is that we tend to have libraries where a lot of magic happens at runtime, based either on the various <T> for generic APIs, or via GetType() on objects that are passed in. Consider the following examples:
Json.NET
// from https://www.newtonsoft.com/json
Product product = new Product();
product.Name = "Apple";
product.Expiry = new DateTime(2008, 12, 28);
product.Sizes = new string[] { "Small" };
string json = JsonConvert.SerializeObject(product);
Dapper
var producer = "Megacorp, Inc.";
var products = connection.Query<Product>(@"
select Id, Name, Expiry
from Products
where Producer = producer",
new { producer }).AsList();
I won’t try to give an exhaustive list, but there are a myriad of libraries - both by Microsoft, or 3rd-party, for a myriad of purposes, that fundamentally fall into the camp of:
At runtime, given some
Type: check the local library type cache; if we haven’t seen thatTypebefore: perform a ton of reflection code to understand the model, produce a strategy to implement the library features on that model, and then expose some simplified API that invokes that strategy.
Behind the scenes, this might be “simple” naive reflection (PropertyInfo.GetValue(), etc), or it might use the Expression API or the ref-emit API (mainly: ILGenerator) to write runtime methods directly, or it might generate C# that it then runs through the compiler (XmlSerializer used to work this way, and may well still do so).
This provides a pretty reasonable experience for the consumer; their code just works, and - sure, the library does a lot of work behind the scenes, but the library authors usually invest a decent amount of time into trying to minimize that so you aren’t paying the reflection costs every time.
So what is the problem?
For many cases: this is fine - we’ve certainly lived well-enough with it for the last however-many years; but: times change. In particular, a few things have become increasingly significant in the last few years:
-
async/awaitIncreasing demands of highly performant massively parallel code (think: “web servers”, for example) has made
async/awaithugely important; from the consumer perspective, it is easy to think that this is mostly a “sprinkle in someasync/awaitkeywords” (OK, I’m glossing over a lot of nuance here), but behind the scenes, the compiler is doing a lot - like a real lot of work for us. If you’re in theExpressionorILGeneratormind-set, switching fully toasync/awaitis virtually impossible - it is just too much. At best, you can end up with someasyncshell library codes that calls into some generatedFunc<...>/Action<...>code, but that assumes that the context-switch points (i.e. the places where you’d want toawaitetc) can be conveniently mapped to that split. It isn’t assumed that a reflection-heavy library can even be carved up in this way. -
AOT platforms
At the other end of the spectrum, we have AOT devices - think “Xamarin”, “Unity”, etc. Running on a small device can mean that you have reduced computational power, so you start noticing the time it takes to inspect models at runtime - but they also often have deliberately restricted runtimes that prevent runtime code generation. This means that you can probably get away with the naive reflection approach (which is relatively slow), but you won’t be able to emit optimized code via
ILGenerator; theExpressionapproach is a nice compromise here, in that it will optimize when it can, but use naive reflection when that isn’t possible - but you still end up paying the performance cost. -
Linkers
Another feature of AOT device scenarios is that they often involve trimmed deployments via a pruning linker, but “Single file deployment and executable” deployments are now a “thing” for regular .NET Core 5 / .NET 6+. This brings two problems:
- we need to work very hard to convince the linker not to remove things that our library is going to need to use at runtime, despite the fact that they aren’t used if you scan the assembly in isolation
- our reflection-heavy library often needs to consider all the possible problematic edge scenarios that could exist, ever, which means it might appear to touch a lot more things than it does, when in reality for the majority of runs it is just going to be asking “do I need to consider this? oh, nope, that’s fine” - because the library appears to touch it
- we thus find ourselves fighting the linker’s tendency to remove everything we need while simultaneously retaining everything that doesn’t apply to our scenario
-
Cold start
It is easy to think of applications as having a relatively long duration, so: cold-start performance doesn’t matter. Now consider things like “Azure functions”, or other environments where our code is invoked for a very brief time, as-needed (often on massively shared infrastructure); in this scenario, cold-start performance translates directly (almost linearly) to throughput, and thus real money
-
Runtime error discovery
One of the problems with having the library do all the model analysis at runtime is that you don’t get feedback on your code until you run it; and sure, you can (and should) write unit/integration tests that push your model through the library in every way you can think of, but: things get missed. This means that code that compiled blows up at runtime, for reasons that should be knowable - an “obvious” attribute misconfiguration, for example.
-
Magic code
Magic is bad. By which I mean: if I said to you “there’s going to be some code running in your application, that doesn’t exist anywhere - it can’t be seen on GitHub, or in your source-code, or in the IDE, or in the assembly IL, or anywhere, and by the way it probably uses lots of really gnarly unusual IL, but trust me it is totally legit” - you might get a little worried; but that is exactly what all of these libraries do. I’m not being hyperbolic here; I’ve personally received bug-reports from the JIT god (AndyAyersMS) because my generated IL used ever so slightly the wrong pointer type in one place, which worked fine almost always, except when it didn’t and exploded the runtime.
There is a different way we can do all of this
Everything above is a side-effect of the tools that have been available to us - when the only tool you’ve had for years has been a hammer, you get used to thinking in terms of nails. For “code first”, that really meant “reflection”, which meant “runtime”. Reflection-based library authors aren’t ignorant of these problems, and for a long time now have been talking to the framework and language teams about options. As the above problem scenarios have become increasingly important, we’ve recently been graced with new features in Roslyn (the C# / VB compiler engine), i.e. “generators”. So: what are generators?
Imagine you could take your reflection-based analysis code, and inject it way earlier - in the build pipe, so when your library consumer is building their code (whether they’re using Visual Studio, or dotnet build or whatever else), you get given the compiler’s view of the code (the types, the methods, etc), and at that point you had the chance to add your own code (note: purely additive - you aren’t allowed to change the existing code), and have our additional code included in the build. That: would be a generator. This solves most of the problems we’ve discussed:
async: our generated code can useasync/await, and we can just let the regular compiler worry about what that means - we don’t need to get our hands dirty- AOT: all of the actual code needed at runtime exists in the assemblies we ship - nothing needs to be generated at runtime
- linkers: the required code is now much more obvious, because: it exists in the assembly; conversely, because we can consider all the problematic edge scenarios during build, the workarounds needed for those niche scenarios don’t get included when they’re not needed, and nor do their dependency chains
- cold start: we now don’t need to do any model inspection or generation at runtime: it is already done during build
- error discovery: our generator doubles as a Roslyn analyzer; it can emit warnings and errors during build if it finds something suspicious in our model
- magic code: the consumer can see the generated code in the IDE, or the final IL in the assembly
If you’re thinking “this sounds great!”, you’d be right. It is a huge step towards addressing the problems described above.
What does a generator look like for a consumer?
From the “I’m an application developer, just make things work for me” perspective, using a generator firstly means adding a build-time package; for example, to add DapperAOT (which is purely experimental at this point, don’t get too excited), we would add (to our csproj):
<ItemGroup>
<PackageReference Include="Dapper.AOT"
Version="0.0.8" PrivateAssets="all"
IncludeAssets="runtime;build;native;contentfiles;analyzers;buildtransitive" />
</ItemGroup>
This package isn’t part of what gets shipped in our application - it just gets hooked into the build pipe. Then we need to follow the library’s instructions on what is needed! In many cases, I would expect the library to self-discover scenarios where it needs to get involved, but as with any library, there might be special methods we need to call, or attributes we need to add, to make the magic happen. For example, with DapperAOT I’m thinking of having the consumer declare their intent via partial methods in a partial type:
[Command(@"select * from Customers where Id=@id and Region=@region")]
[SingleRow(SingleRowKind.FirstOrDefault)] // entirely optional; this is
// to influence what happens when zero/multiple rows returned
public static partial Customer GetCustomer(
DbConnection connection, int id, string region);
If you haven’t seen this partial usage before, this is an “extended partial method” in C# 9, which basically means partial methods can now be accessible, have return values, out parameters, etc - the caveat is that somewhere the compiler expects to find another matching half of the partial method that provides an implementation. Our generator can detect the above dangling partial method, and add the implementation in the generated code. This generated code is then available in the IDE, either by stepping into the code as usual, or in the solution explorer:
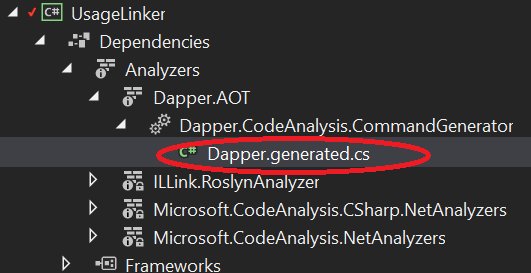
and as a code file:
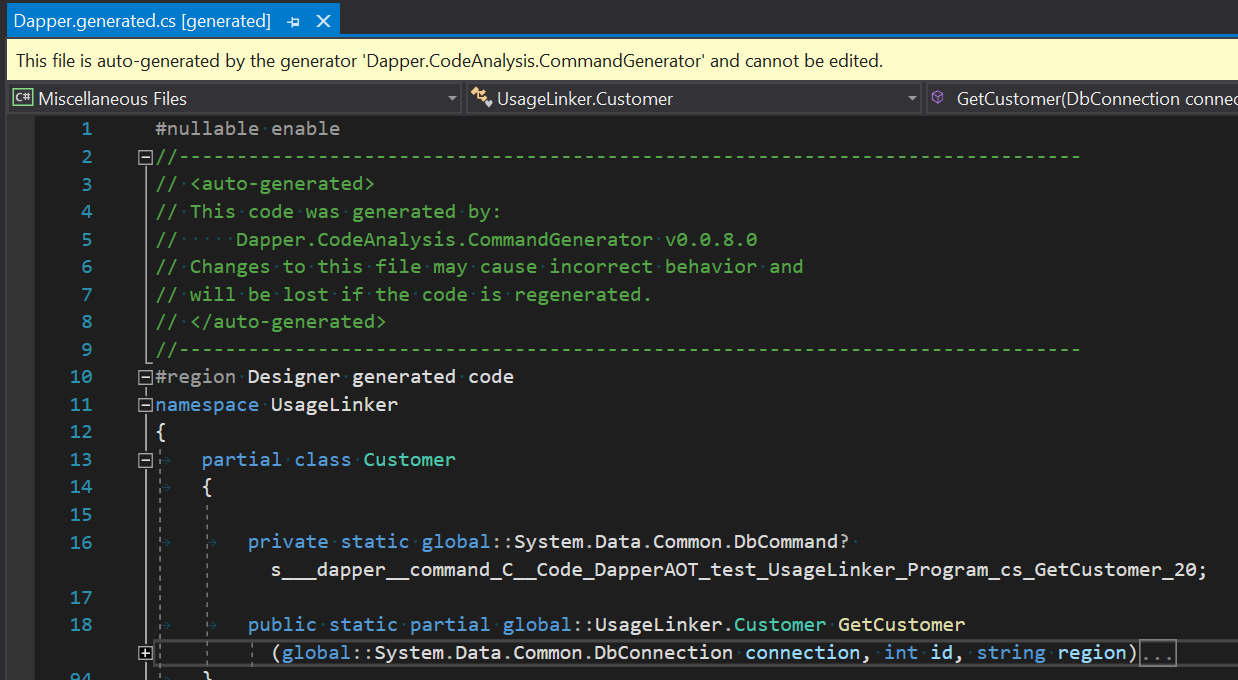
Other libraries may choose other approaches, perhaps using module initializers to register some specific type handlers into a lightweight library, that handle expected known types (as discovered during build); or it could detect API calls that don’t resolve, and add them (either via partial types, or extension methods) - like a custom dynamic type, but where the convention-based APIs are very real, but generated automatically during build. But the theme remains: from the consumer perspective, everything just works, and is now more discoverable.
What does a generator look like for a library author?
Things are a little more complicated for the library author; the Roslyn semantic tree is similar to the kind of model you get at runtime - but it isn’t the same model; in particular, you’re not working with Type any more, you’re working with ITypeSymbol or (perhaps more commonly) INamedTypeSymbol. That’s because the type system that you’re inspecting is not the same as the type system that you’re running on - it could be for an entirely different framework, for example. But if you’re already used to complex reflection analysis, most things are pretty obvious. It isn’t very hard, honest. Mostly, this involves:
- implementing
ISourceGenerator(and marking that type with[Generator]) - implementing
ISyntaxReceiverto capture candidate nodes you might want to look at later - implementing
ISourceGenerator.Initializeto register yourISyntaxReceiver - implementing
ISourceGenerator.Executeto perform whatever logic you need against the nodes you captured - calling
context.AddSourcesome number of times to add whatever file(s) you need
I’m not going to give a full lesson on “how to write a generator” - I’m mostly trying to set the scene for why you might want to consider this, but there is a Source Generators Cookbook that covers a lot, or I humbly submit that the DapperAOT code might be interesting (I am not suggesting that it does everything the best way, but: it kinda works, and shows input-source-file-based unit testing etc).
This all sounds too good to be true? What is the catch?
Nothing is free. There’s a few gotchas here.
- It is a lot of re-work; if you have an existing non-trivial library, this represents a lot of effort
- You may also need to re-work your main library, perhaps splitting the “reflection aware” code and “making things work” code into two separate pieces, with the generator-based approach only needing the latter half
- Some scenarios may be hard to detect reliably during code analysis - where your code is seven layers down in generic types and methods, for example, it may be hard to discover all of the original types that are passed into your library; and if it is just
object: even harder; we may need to consider this when designing APIs, or provide fallback mechanisms to educate the generator (for example,[model:GenerateJsonSerializerFor(typeof(Customer))]) - There are some things we can’t do in C# that we can do in IL; change
readonlyfields, callinit/get-only properties, bypass accessibility, etc; in some cases, we might be able to generateinternalconstructors in anotherpartial class(for example), that allows us to sneak past those boundaries, but in some other cases (where the type being used isn’t part of the current compilation, because it comes from a package reference) it might simply be that we can’t offer the exact same features (or need to use a fallback reflection scenario) - It is
C# specific(edit: C# and VB, my mistake!); this is a huuuuuge “but”, and I can hear the F#,VB, etc developers gnashing their teeth already; there’s a very nuanced conversation here about whether the advantages I’ve covered outweigh the disadvantages of not being able to offer the same features on all .NET platforms - It needs up-to-date build tools, which may limit adoption (note: this does not mean we can only use generators when building against .NET 6 etc)
- We have less flexibility to configure things at runtime; in practice, this isn’t usually a problem as long as we can actually configure it, which can be done at build-time using attributes (and by using
[Conditional(...)]on our configuration attributes, we don’t even need to include them in the final assembly - they can be used by the generator and then discarded by the compiler)
That said, there’s also some great upsides - during build we have access to information that doesn’t exist in the reflection model, for example the name parts of value-tuples (which are exposed outwards via attributes, but not inwards; libraries are inwards, from this perspective), and more reliable nullability annotation data when calling generic APIs with nullability.
Summary
I genuinely think we should be embracing generators and reducing or removing completely our reliance on runtime reflection emit code. I say this as someone who has built a pretty successful niche as an expert in those areas, and would have to start again with the new tools - I see the benefits, despite the work and wrinkles. Not only that, I think there is an opportunity here (with things like “extended partial methods” etc) to make our application code even more expressive, rather than having than having to worry about dancing around library implementation details.
But I welcome competing thoughts!